Project 4: Proof statistically that unsupervised representation learning enhance classifier performance
Full Implementation and details
Problem Statement
Design and train a network that combines supervised and unsupervised architecture in one model to achieve a classification task
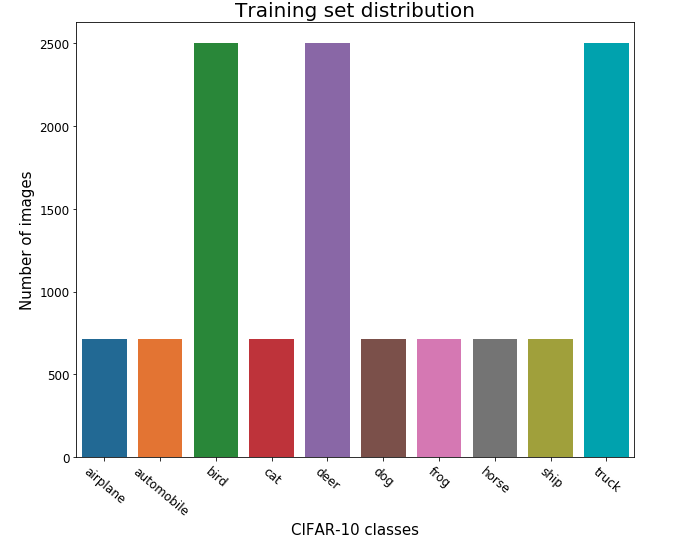
Dataset
- Strictly Imbalance CIFAR-10 dataset
Architecture
- Convolutional Neural Network based AutoEncoder
- Encoder architecture as classifer with additional dense layer to classify images
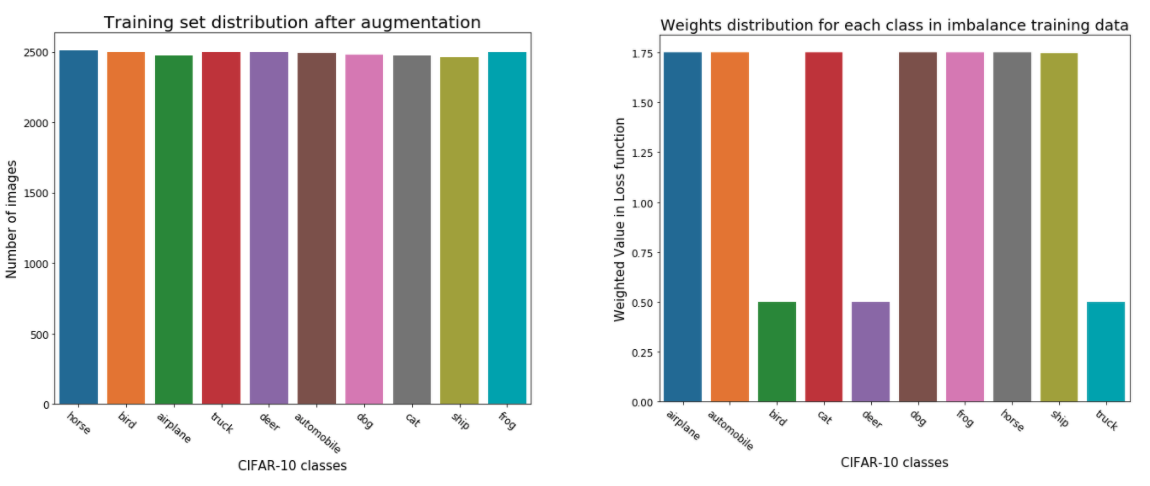
Handling Imbalance dataset
- Proper distribution of weights for each class
- Data augmentation emphasize on minority classes
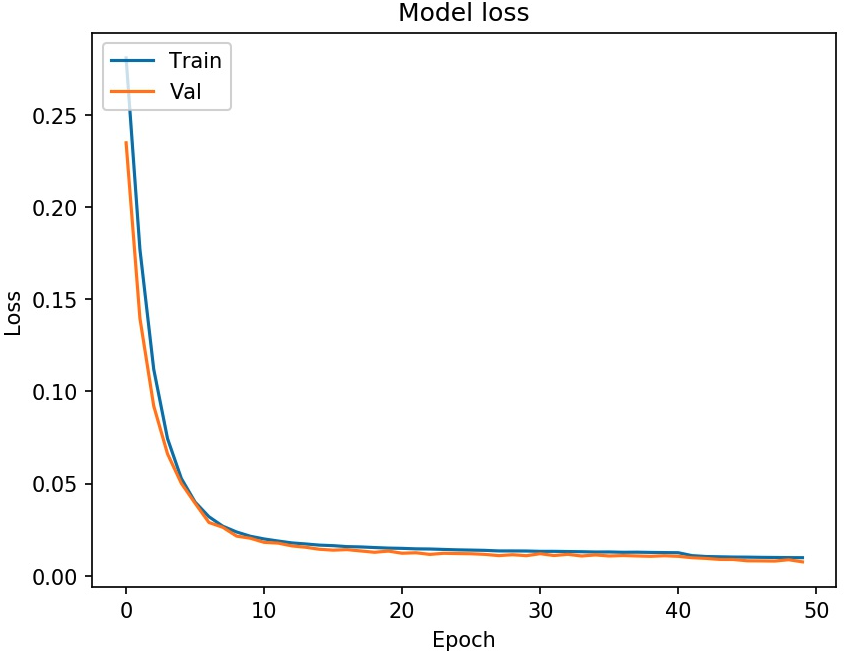
AutoEncoder Training Results
- Reconstruction of images with Mean-Squared-Error loss

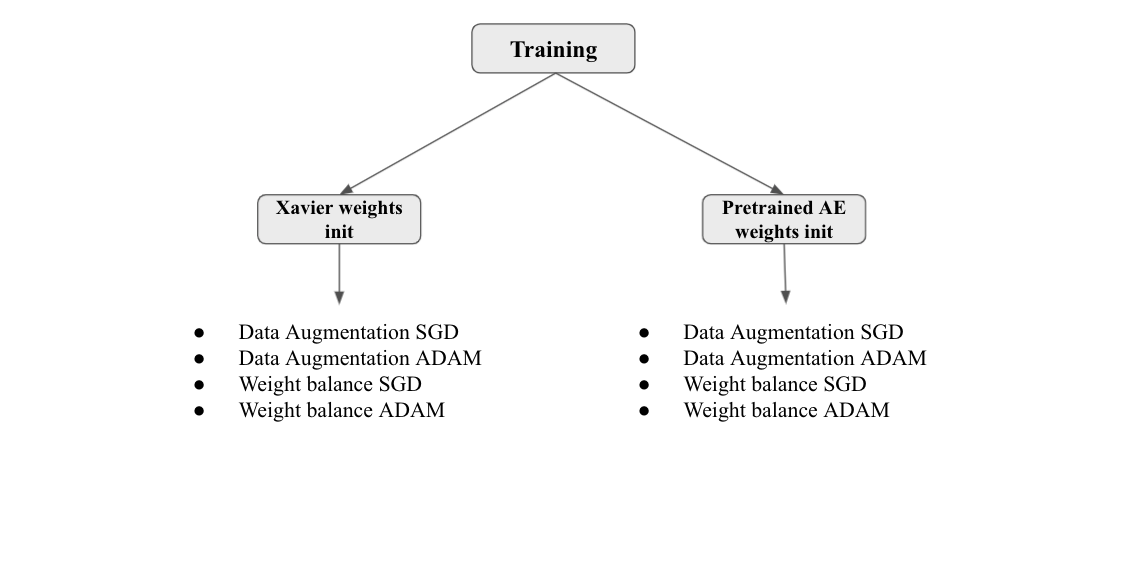
Classifier Training Scenarios
Experiment Results
Accuracy on CIFAR-10 test dataset on 10,000 images
| Training Methodology | Xavier Init | Pretrained Autoencoder Init | Avg Improvement |
|---|---|---|---|
| Data Augmentation SGD | 0.72 | 0.76 | +4% |
| Data Augmentation ADAM | 0.67 | 0.74 | +7% |
| Weighted Loss SGD | 0.61 | 0.74 | +13% |
| Weighted Loss ADAM | 0.66 | 0.72 | +6% |
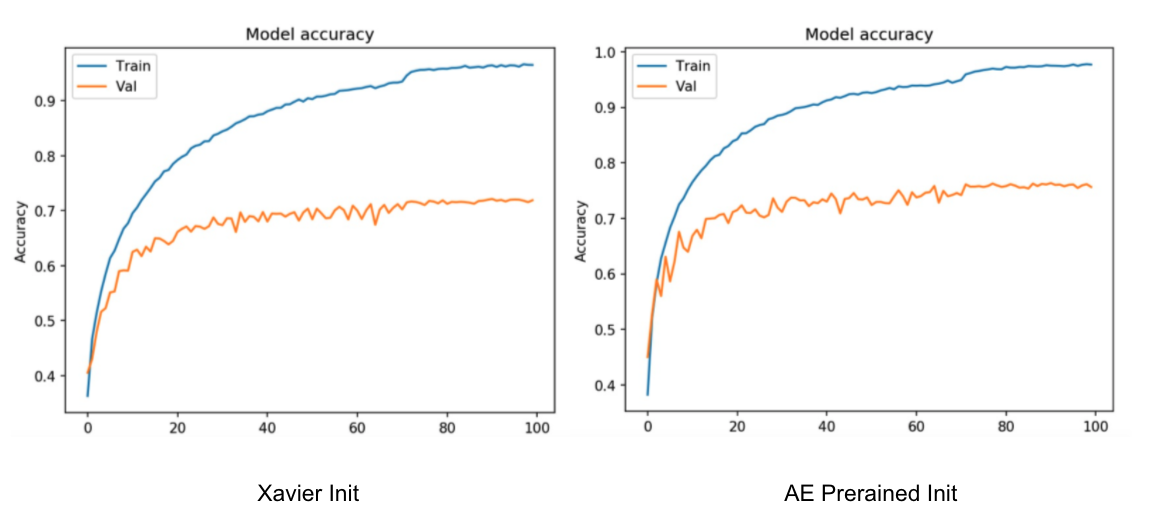
Result of training and val (Test) data by data augmentation with SGD optimizer using pretrained autoencoder initialization
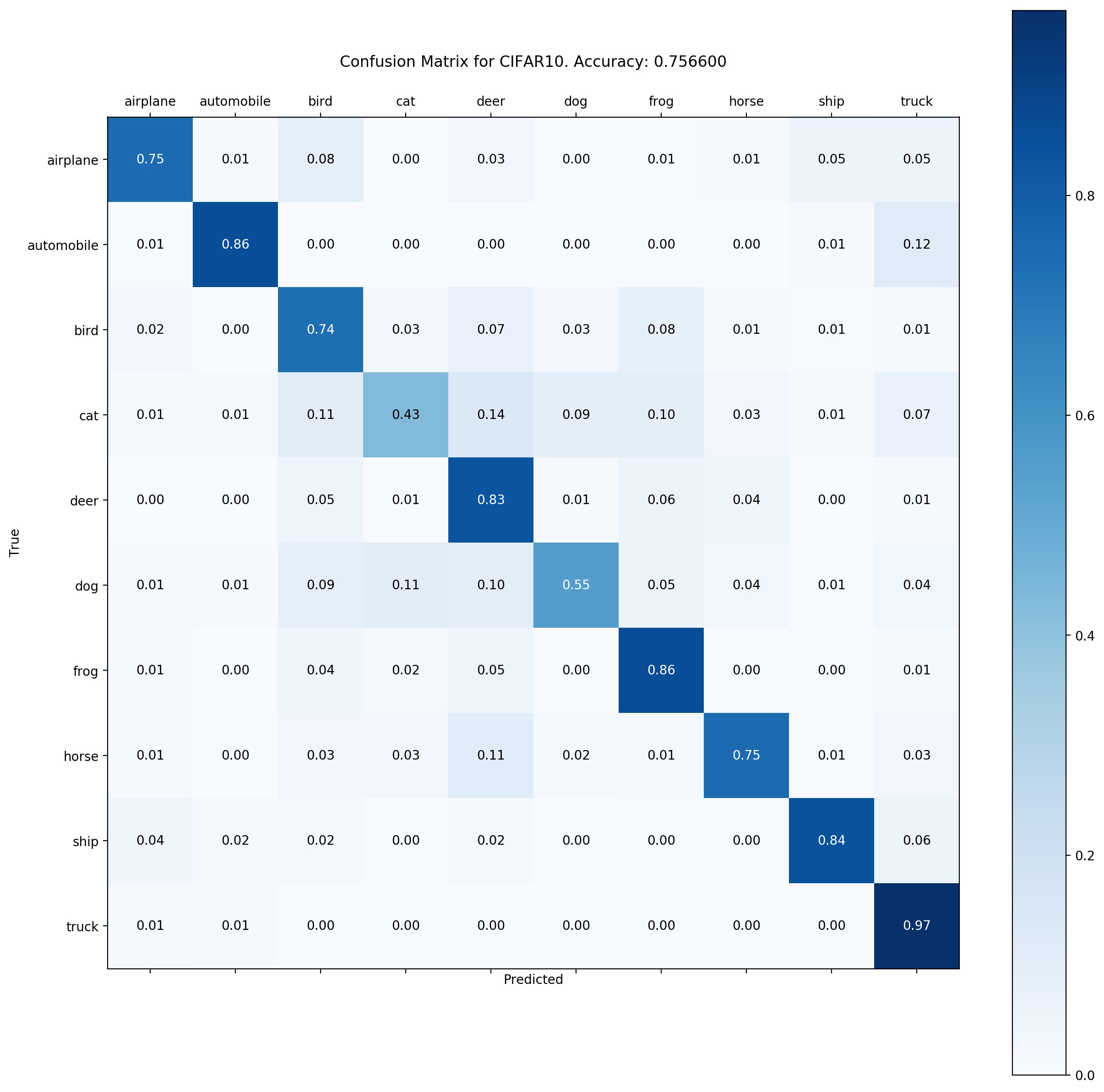
Confusion Matrix (% accuracy in each classes on test data)
Statistical Significance (T-Test)
The t-test tells you how significant the difference between groups are; In other words it lets you know if those differences could have happened by chance. Above experiment results are divided into two groups which are Xavier Initialization and Autoencoder pretraininng Initialization for classifier
Null Hypothesis: Using pretrained autoencoder, average experimental accuracy won’t change. Difference of accuracies occur by chance
Alternative Hypothesis: Using pretrained autoencoder, average experimental accuracy change. In other words, difference of accuracies did not occur by chance
Significance Level: Usually defined at 5%
Performed T-test: P-value was calculated based on above experiment data and it comes out 0.02295823029 which indicate approximately 2.3%. P-value is less than significance level and we can conclude that we have enough evidence to reject null hypothesis.